


The world of artificial intelligence (AI) has been abuzz with debates and discussions surrounding the reliability of rankings on a popular chatbot leaderboard. Sara Hooker, the head of Cohere’s research division, has voiced her apprehensions, labeling the situation as a “crisis” in AI development.
In a collaborative effort with researchers from Cohere, as well as prestigious universities, Hooker co-authored a study shedding light on alleged manipulations by major AI companies on the LM Arena platform. This platform is renowned for ranking large language models (LLMs) through crowd-sourcing. The study suggests that these companies have been engaging in tactics to artificially boost their rankings.
“I hope that there is an active discussion and a sense of integrity that maybe this paper has spurred,” Hooker emphasized during an interview.
The research paper titled “The Leaderboard Illusion” points out significant transparency and trust issues within LM Arena, eroding its credibility among academia, businesses, and the general public. Despite being published on ArXiv—an open-access platform—the paper is yet to undergo peer review.
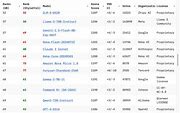
LM Arena’s “Chatbot Arena” emerged as a prominent benchmark for evaluating LLMs after originating from a research project at the University of California, Berkeley. Users engage in comparing two chatbots head-to-head in battles where one emerges victorious based on user votes.
However, concerns were raised regarding leading AI developers such as Meta, Google, and OpenAI allegedly receiving preferential treatment on LM Arena. These developers reportedly had opportunities for extensive pre-release testing not available to others. The authors argue that such practices unfairly disadvantage competitors.
The spotlight fell on Meta when it was discovered that they conducted 27 private tests of Llama-4 before unveiling its final model which secured a high rank upon release. Subsequently caught uploading an optimized version for human preference led to policy updates by LM Arena to prevent such occurrences in the future.
Responding to criticisms raised by LM Arena post-publication of the research paper, Cohere’s Hooker expressed hope for constructive dialogue towards reforming the arena’s processes: “I’m hoping we have a more substantial conversation…This was an uncomfortable paper to write.”
Suggestions put forth by the authors include capping private variant model submissions and banning score retractions while advocating for enhanced sampling fairness and increased transparency in model removal protocols.
Meanwhile, Cohere Labs—a non-profit research lab affiliated with Toronto-based LLM developer Cohere—has been making strides within Canada’s competitive AI landscape despite not clinching top spots on Chatbot Arena’s leaderboard. Their Command A model holds 19th place but boasts superior performance compared to GPT-4o from OpenAI last November and DeepSeek’s v3.
Deval Pandya from Vector Institute underscores the importance of ongoing enhancements in AI model evaluations amid these revelations. Vector Institute—a non-profit institute founded by industry luminaries—recently launched its own evaluation framework encompassing 11 prominent AI models across various scientific benchmarks rather than relying solely on dynamic crowd-sourced data like Chatbot Arena does.
Pandya advocates for objectivity in evaluating AI progress particularly crucial when companies are incentivized to showcase only their best outcomes especially when publicly traded entities are involved. He stresses the significance of independent projects akin to Vector’s broadening assessment scopes beyond mainstream models’ evaluations aiming at democratizing evaluation standards within the industry.






